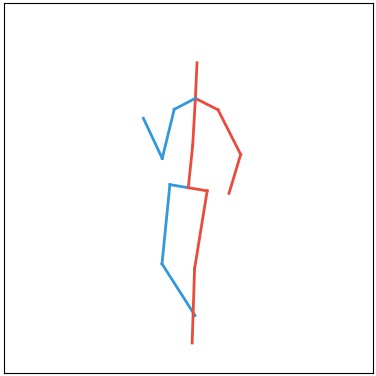
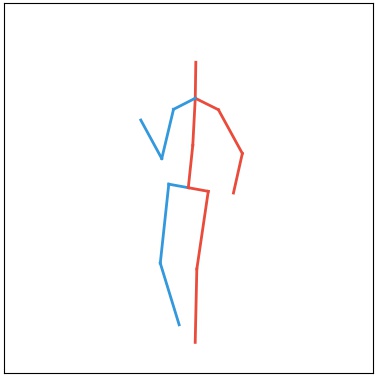
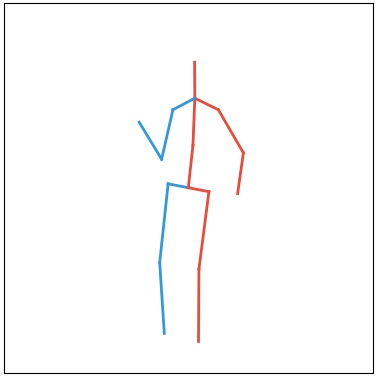
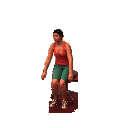Quanlitative Results
Note: Each following section corresponds to a generation task, namely video generation, video prediction and video completion. Columns named "Real" stands for real data (for your reference). Columns named "Input-n" stands for input frames where n is the frame number used (e.g. “Input-1” means the 1st frame in a video is used as input/constraint). The other columns show the qualitative results of each method. For our method we also show our pose sequence results, denoted as “Ours-Pose”. Each row corresponds to an action class, from top to bottom: Walking, Direction, Greeting, Sitting, Sitting Down.
Illustration of Our Pipeline
Video Generation Pipeline
Video Prediction Pipeline
Video Completion Pipeline
$z_0 + z\: (concatenation)$
stacked hourglass pose estimation
stacked hourglass pose estimation
Pose Sequence Generation Process
Constrained Pose Sequence Generation Process
Constrained Pose Sequence Generation Process
Skeleton to Image
Skeleton to Image
Skeleton to Image