Abstract
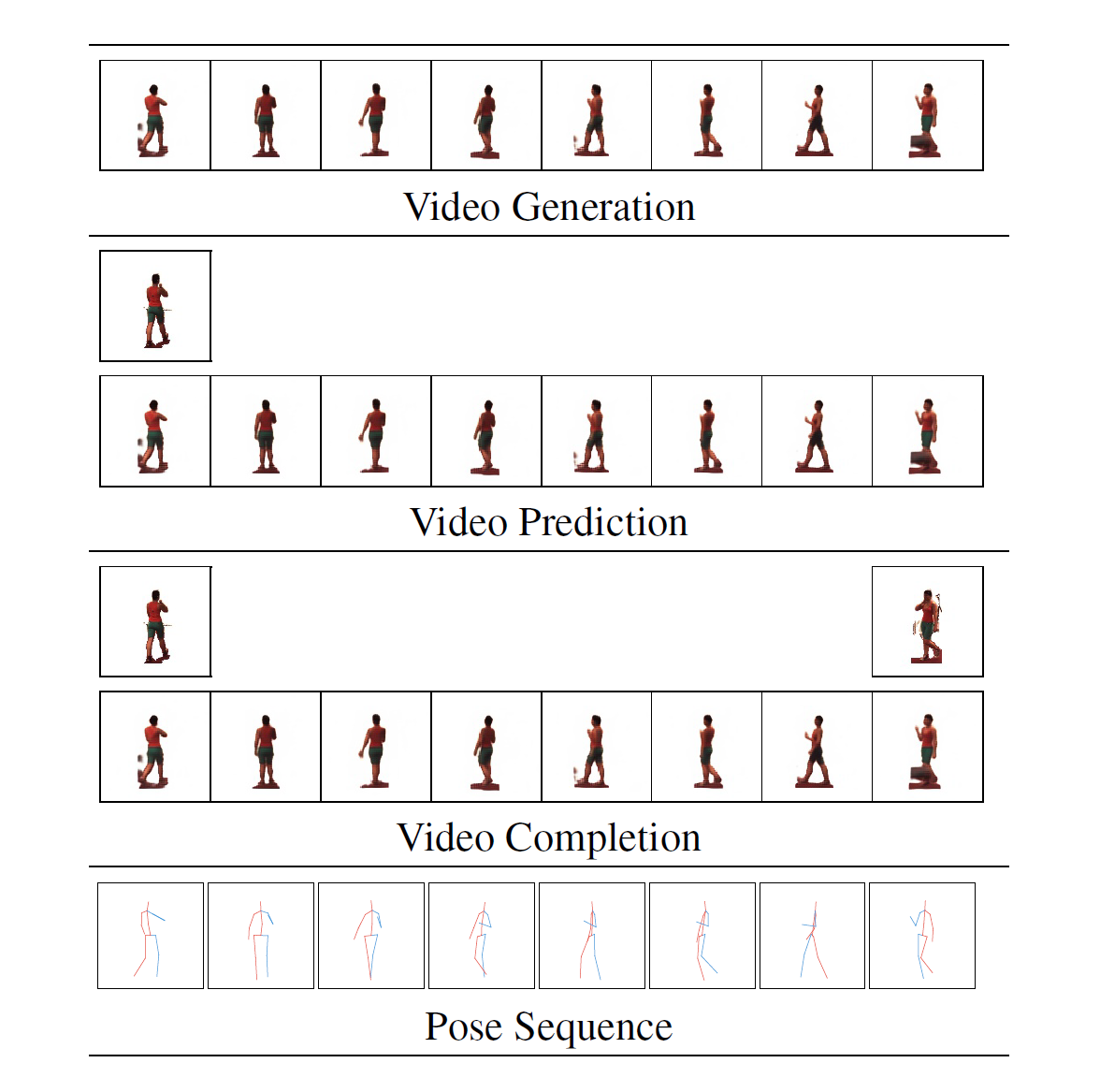
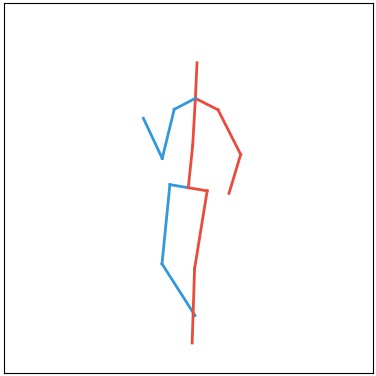
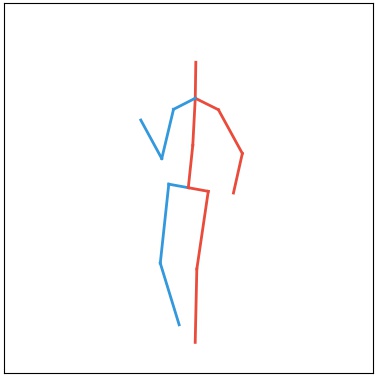
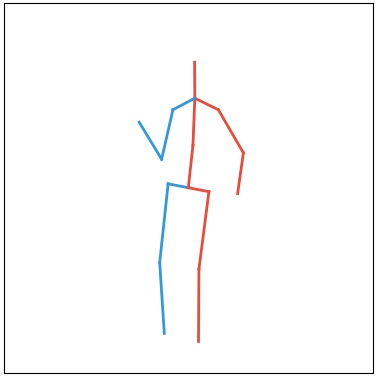
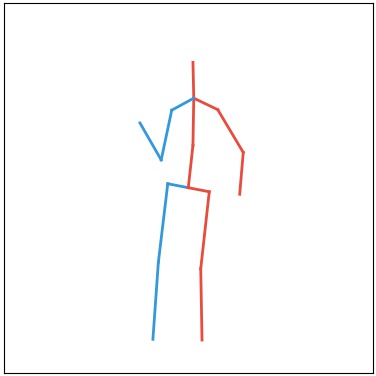
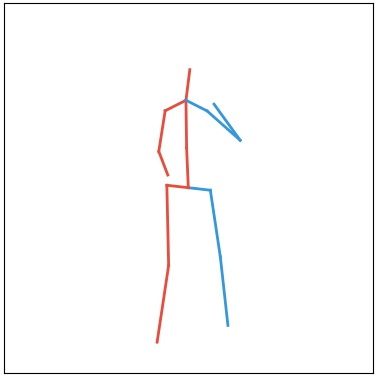
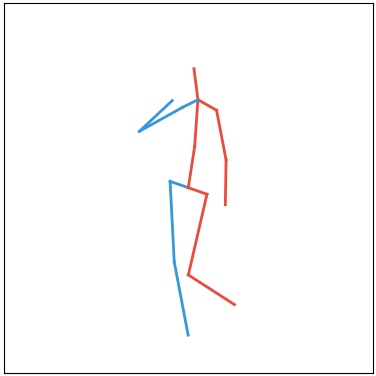
Current deep learning results on video generation are limited while there are only a few first results on video prediction and no relevant significant results on video completion. This is due to the severe ill-posedness inherent in these three problems. In this paper, we focus on human action videos, and propose a general, two-stage deep framework to generate human action videos with no constraints or arbitrary number of constraints, which uniformly address the three problems: video generation given no input frames, video prediction given the first few frames, and video completion given the first and last frames. To make the problem tractable, in the first stage we train a deep generative model that generates a human pose sequence from random noise. In the second stage, a skeleton-to-image network is trained, which is used to generate a human action video given the complete human pose sequence generated in the first stage. By introducing the two-stage strategy, we sidestep the original ill-posed problems while producing for the first time high-quality video generation/prediction/completion results of much longer duration. We present quantitative and qualitative evaluation to show that our two-stage approach outperforms state-of-the-art methods in video generation, prediction and video completion.
Download Paper
Deep Video Generation, Prediction and Completion of Human Action Sequences
Haoye Cai*, Chunyan Bai*, Yu-Wing Tai, Chi-Keung Tang (* equal contribution)
Preprint: arXiv:1711.08682 (under review for CVPR 2018)